Je li broj potvrđenih slučajeva COVID-19 u Hrvatskoj manji, jednak ili veći od očekivanog? Utemeljeni odgovor na to pitanje moguće je dati tek po procjeni očekivanog broja potvrđenih slučajeva koju se izvodi iz podataka o stanju u drugim državama. U ovom osvrtu se iznosi pokušaj da se to učini na temelju rezultata statističkog modela razvoja epidemije na području Europe od 20. veljače 2020. godine, trenutka kada je došlo do naglog porasta broja zaraženih u Italiji, a ubrzo potom i drugdje.
Višerazinskim regresijskim modelom je povezana promjena u stopi potvrđenih slučajeva COVID-19 s protekom vremena od pojave prvog slučaja u pojedinoj državi, uz uvažavanje razlika u razvoju trenda. Model uzima u obzir podatke o razvoju epidemije na prostoru Europe od 20. veljače do 8. ožujka 2020. godine (podaci za stanje zaključno s 8 sati ujutro). Izvor epidemioloških podataka je Europen Centre for Disease Control, a izvor podataka o brojnosti stanovništa baza podataka Svjetske banke, uz nekoliko iznimaka za države za koje podaci o brojnosti stanovništva nisu dostupni i koji su dopunjeni iz drugih izvora. Više detalja o modelu navedeno je u prilogu na kraju ovog osvrta.
Modelska procjena srednje vrijednosti očekivanog broja potvrđenih slučajeva COVID-19, kredibilni interval te procjene (95%) i izvorni podaci o objavljenom broju potvrđenih slučajeva prikazani su za nekoliko nasumce odabranih država na slici 1, a cjelovit prikaz je dostupan ovdje. Modelska krivulja koja predstavlja očekivani broj potvrđenih slučajeva zadovoljavajuće opisuje promjenu u većini država, uz iznimke koje upućuju na vjerojatne posebnosti u obrascu razvoja epidemiološkog stanja ili odgovora.
{kind=link}
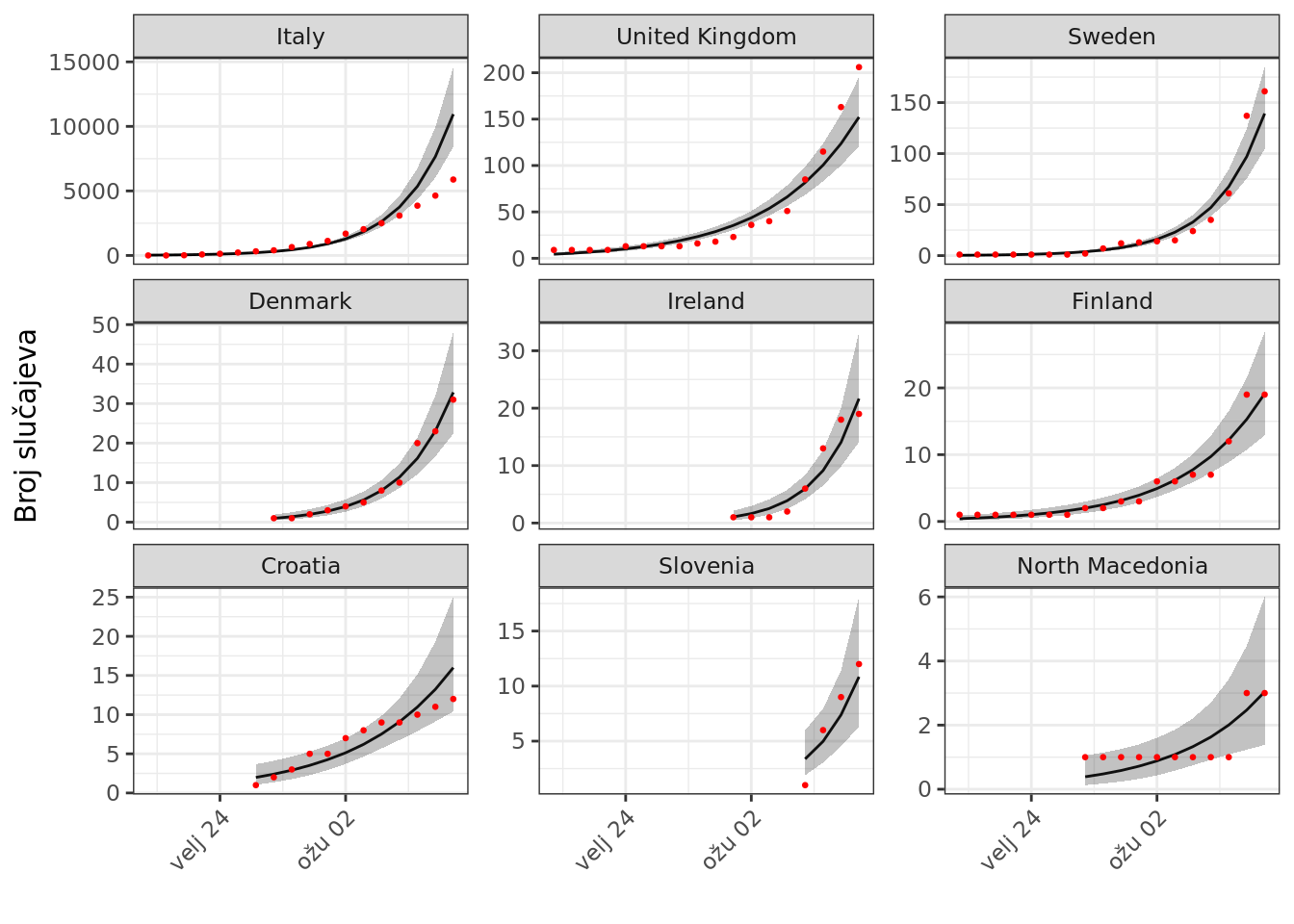
Slika 1: Modelska procjena i izvorne vrijednosti broja potvrđenih slučajeva COVID-19 u pojedinim državama.
Na temelju rezultata statističkog modela moguće je izvesti dvije vrste procjene koje daju odgovor na donekle različita pitanja:
Prva vrsta procjene (“A”) pruža odgovor koliko se objavljeni broj povrđenih slučajeva razlikuje od broja kojeg se može očekivati na temelju dosadašnjeg razvoja trenda u pojedinoj državi.
Druga vrsta procjene (“B”) pruža odgovor koliko se objavljeni broj potvrđenih slučajeva razlikuje od očekivanog broja u državi određene brojnosti stanovništva nakon određenog proteka vremena od prvog zabilježenog slučaja. Na primjeru Hrvatske, ova vrsta procjene govori koliko se potvrđenih slučajeva može očekivati u državi koja ima 4.1 milijun stanovnika, a u kojoj je prvi slučaj zabilježen prije 12 dana.
Prema procjeni A, podatak o 12 potvrđenih slučajeva u Hrvatskoj na dan 8. ožujka nalazi se unutar kredibilnog intervala modelske procjene koja uzima u obzir dosadašnji tijek porasta broja potvrđenih slučajeva u Hrvatskoj. Očekivani broj potvrđenih slučajeva na taj dan iznosi 16 [CI 95% 10, 25], a vjerojatnost da je objavljeni broj manji od srednje vrijednosti modelske procjene iznosi 91%.
Prema procjeni B, očekivani broj potvrđenih slučajeva u državi koja ima 4.1 milijun stanovnika, a u kojoj je prvi slučaj zabilježen prije 12 dana, na dan 8. ožujka iznosi 31 [CI 95% 0, 7461]. Objavljeni podatak o 12 potvrđenih slučajeva u Hrvatskoj nalazi se unutar kredibilnog intervala ove modelske procjene, uz vjerojatnost od 60% da je manji od njene srednje vrijednosti.
Rezultati obje procjene grafički su predočeni na slici 2. Raspodjela vjerojatnosti procjene B je nepotpuno prikazana radi preglednosti.
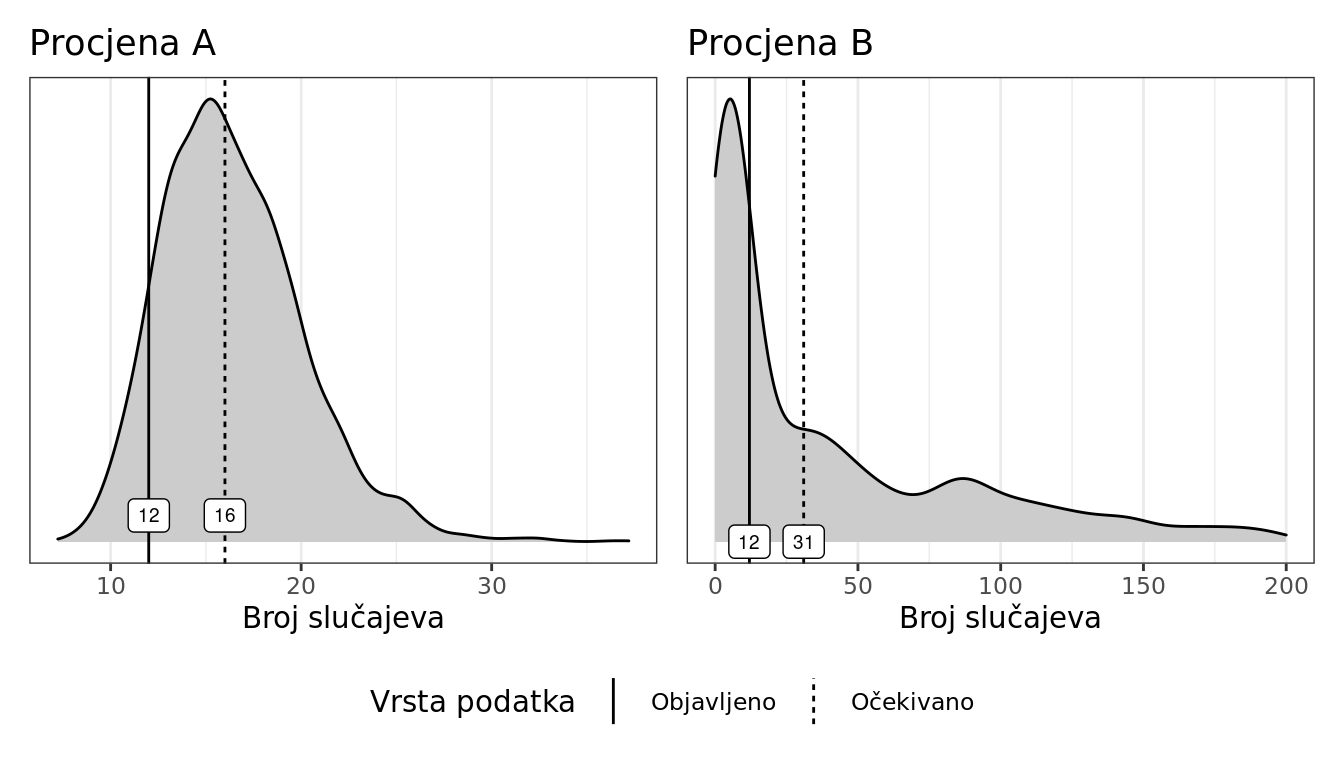
Slika 2: Srednja vrijednost i raspodjela posteriorne vjerojatnosti obje modelske procjene očekivanog broja potvrđenih slučajeva COVID-19 u Hrvatskoj.
Na slici 3. prikazani su grupni (varijabilni) modelski koeficijenti na razini država koji upućuju na razlike u stopi potvrđenih slučajeva i razlike u naglašenosti očekivanog trenda porasta. Hrvatska je približno prosječna kad je riječ o iznosu stope potvrđenih slučajeva, uz prosječan trend porasta.
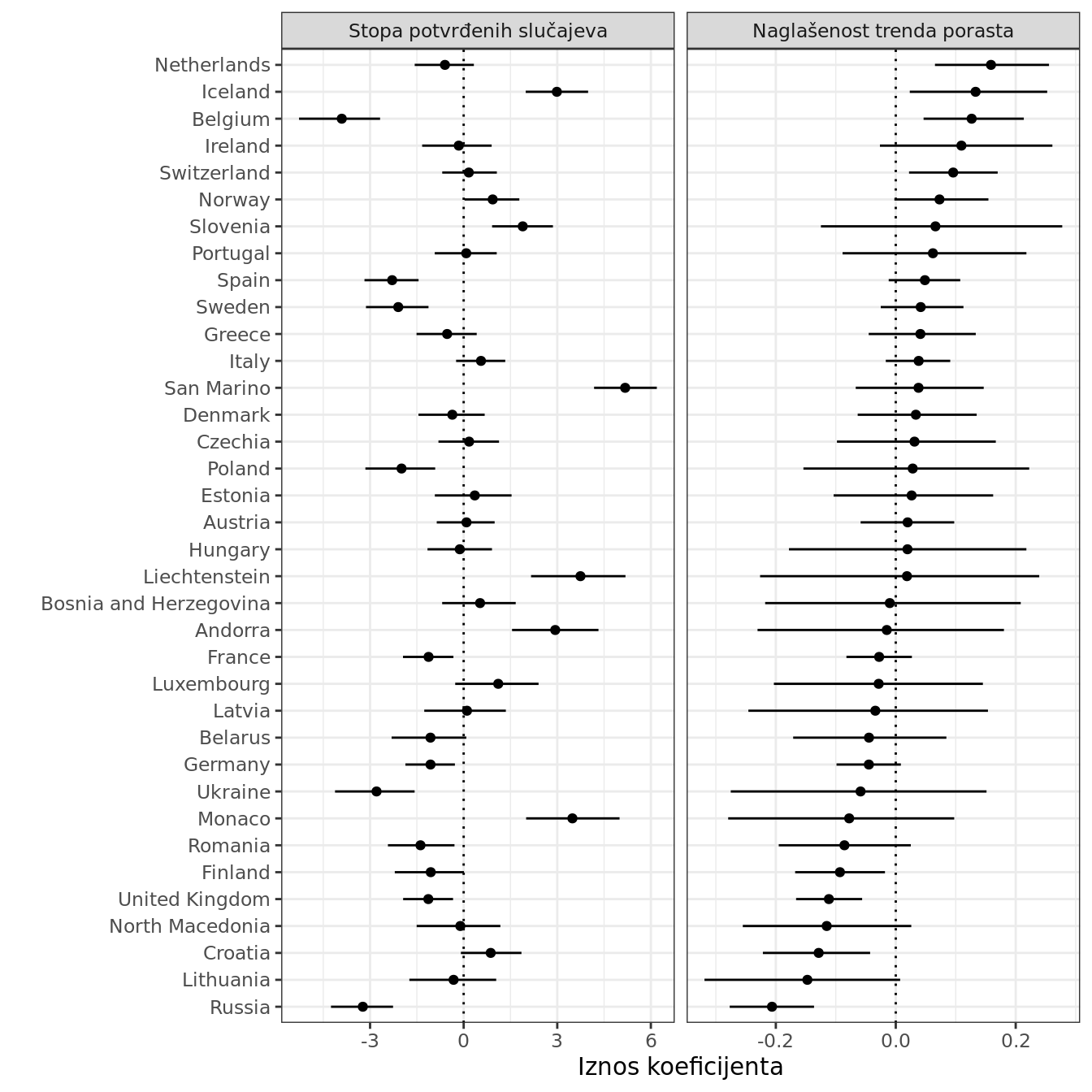
Slika 3: Grupi (varijabilni) koeficijenti za pojedine države koji opisuju relativna odstupanja u stopi potvrđenih slučajeva i naglašenosti trenda porasta.
Potrebno je navesti nekoliko napomena o tumačenju rezultata ove analize:
Procjena očekivanog broja potvrđenih slučajeva COVID-19 nije procjena broja ukupno zaraženih osoba jer nije vjerojatno da broj potvrđenih slučajeva u ijednoj državi odgovara broju stvarno zaraženih osoba. Upravo dosadašnji nagli razvoj epidemije upućuje da zaraženih u pravilu ima više nego je potvrđeno testiranjem, pa je iz tog razloga i ova modelska procjena očekivanog broja potrvđenih slučajeva vrlo vjerojatno niža od broja ukupno zaraženih osoba.
Protokol testiranja nije jednak u svim državama i podložan je izmjenama kroz vrijeme. U nekim slučajevima njegova uspješnost da zahvati određeni udjel stvarno zaraženih osoba je veća, u drugim slučajevima je manja. Informacija o vrsti, obuhvatu i uspješnosti protokola nije ugrađena u predstavljeni statistički model i stoga nije moguće izravno tumačiti očekivani broj potvrđenih slučajeva ni kao razmjerni odraz brojnosti stvarno zaraženih osoba.
Dinamika širenja COVID-19 se vjerojatno razlikuje u pojedinim državama i opravdano je očekivati da je broj stvarno zaraženih osoba, a posredno i potvrđenih slučajeva, manji u područjima koja su udaljenija ili slabije povezana sa glavnim žarištima. Informacija o toj udaljenosti i povezanosti također nije ugrađena u model, koji u tom smislu pretpostavlja jednakost svih jedinica analize.
Prilog
Statistički model povezuje objavljeni broj potvrđenih slučajeva (count) s protekom vremena (time) na ukupnoj razini i razini pojedinih država (country) s obzirom na broj njenih stanovnika (population). Pri postavljanju modela pretpostavljena je negativna binomijalna raspodjela broja slučajeva i slabo informativna, regularizirajuća prethodna vjerojatnost raspodjele modelskih parametara. Razdoblje od pojave prvog slučaja određeno je u maksimalnom iznosu (18 dana) u državama gdje je i prije 20. veljače bilo potvrđenih slučajeva . Koeficijenti modelskih parametara su izračunati MCMC algoritmom pomoću brms sučelja za STAN.
U nastavku je naveden sažeti prikaz postavki modela i izračunatih parametara, a na slici 4. grafički prikaz populacijskih uvjetnih učinaka prediktora.
## Family: negbinomial
## Links: mu = log; shape = identity
## Formula: cases | rate(population) ~ time + (time | country)
## Data: data (Number of observations: 387)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Group-Level Effects:
## ~country (Number of levels: 36)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sd(Intercept) 2.11 0.29 1.63 2.74 1.00 1228 2096
## sd(time) 0.11 0.02 0.08 0.16 1.00 1596 2320
## cor(Intercept,time) 0.03 0.22 -0.40 0.45 1.00 1723 2676
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept -15.60 0.36 -16.32 -14.87 1.01 549 1050
## time 0.32 0.02 0.27 0.37 1.00 1467 2003
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## shape 15.03 2.51 10.77 20.60 1.00 5300 3076
##
## Samples were drawn using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).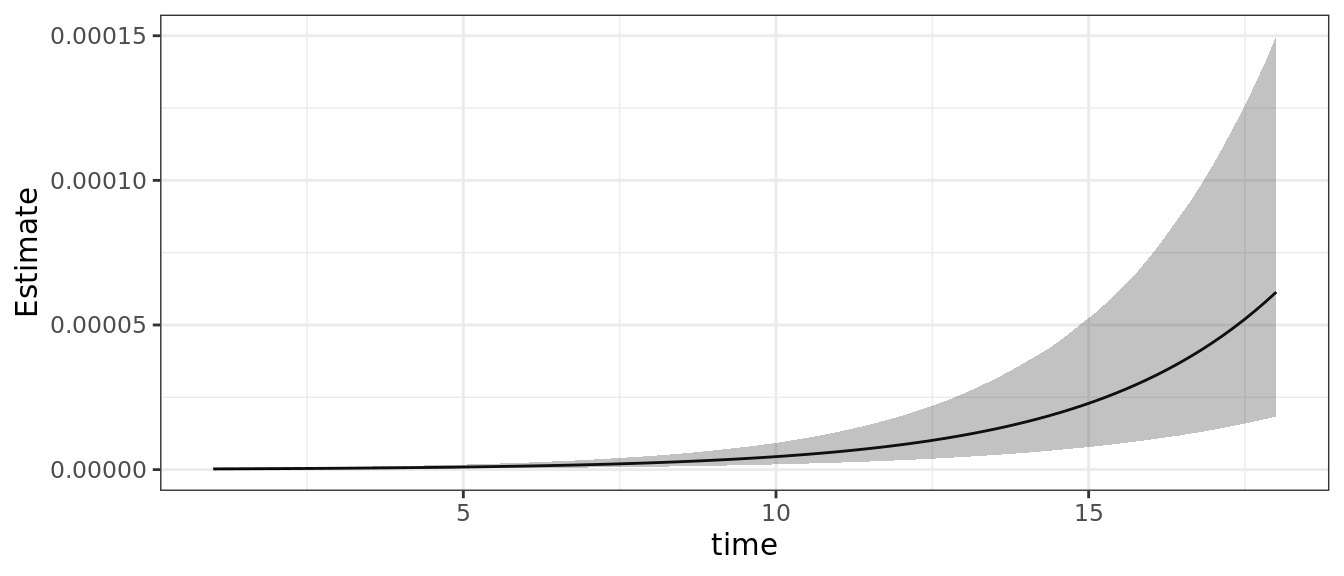
Slika 4: Populacijski uvjetni učinci prediktora.